Calculating Pi by finding the area under a bell curve
For Pi Day in 2021, I decided to use a lesser-known method of calculating the digits of Pi.
Recap on probability density functions
In statistics, a probability density function (PDF) of a continuous random variable \(r\) is a curve whose height, at any given sample along the \(x\)-axis, represents the relative likelihood that \(r\) equals that sample.
For example, take \(r\) to be a random stranger’s height in inches. Now suppose the PDF of \(r\) looks like this:

Figure 1: A PDF of human heights
What this curve tells us is the probability this random stranger’s height is around \(68"\) is relatively high. The chance their height is above \(75"\) or below \(60"\) is more unlikely.
The mean average height of strangers is exacly in the centre peak of this PDF, while about \(95\%\) of the values lie within two standard deviations. It turns out this PDF is exactly the kind of shape of a normal distribution or bell curve.
On normal distributions
A normal distribution is the kind of distribution you get with a large number of independent samples of a random variable. For example, the heights or weights of random citizens picked off a street.
The general form of normal distribution’s PDF is
\[y = \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2}\left( \frac{x - \mu}{\sigma} \right)^2}\]where \(\mu\) is the mean of the distribution, and \(\sigma\) is the standard deviation.
The area under a normal distribution
The factor of \(1/\left( \sigma \sqrt{2 \pi} \right)\) ensures the area under this curve is exactly \(1\). The area must be \(1\) since it is the sum of probabilities in a distribution. Without this factor, the peak of the graph would be \(1\) and the total area would be \(\sigma \sqrt{2 \pi}\). This is because we have
\[\int_{-\infty}^{\infty} {\frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2}\left( \frac{x - \mu}{\sigma} \right)^2}} = 1,\]so, moving the constant factor out of the integral and dividing it through on both sides gives
\[\int_{-\infty}^{\infty} e^{-\frac{1}{2}\left( \frac{x - \mu}{\sigma} \right)} = \sigma \sqrt{2 \pi}.\]
Figure 2: The PDF from before, but without the normalisation factor, making its peak 1 and its area a factor of \(\sqrt{2\pi}\).
The goal
Our goal is to take a set of normally distributed data (the heights and weights of \(25,000\) humans), organise the data as a histogram, and “squish” the histogram down so its peak is at \(1\). Then we will have something like Figure 2 which we can take the area under and hopefully get \(\sigma \sqrt{2 \pi}\). Since we will know \(\sigma\) (the standard deviation, we can calculate), we can divide, square, and half the area to get \(\pi\).
The code
I will be coding this in Python. Firstly, I needed to download the dataset and store it as a CSV. I’ve called this heights-weights.csv so I can read from it in my program.
import csv
import numpy as np
N_ROWS = 25000
heights = np.empty(N_ROWS)
weights = np.empty(N_ROWS)
with open('heights-weights.csv', 'r') as f:
rows = csv.reader(f)
for i, row in enumerate(rows):
if i == 0: # Discard the first row (header)
continue
heights[i - 1] = row[1]
weights[i - 1] = row[2]
if i >= N_ROWS: # Safety check - check the number of rows in your CSV first and assign N_ROWS
break
print(heights)
print(weights)
$ python pi.py
[65.78331 71.51521 69.39874 ... 64.69855 67.52918 68.87761]
[112.9925 136.4873 153.0269 ... 118.2655 132.2682 124.8742]
Cool, so we’ve read our CSV file and stored the data of each column into Numpy arrays. For now, let’s just focus on the height data and plot it in a histogram to see if we do indeed have a bell shape.
We’ll need to import pyplot to do this for us.
import matplotlib.pyplot as plt
And now let’s add the following to our code:
N_BINS = 1000
y, x = np.histogram(heights, bins=N_BINS)
x = x[1:] # One too many bin offsets
plt.plot(x, y)
plt.show()
Run the program and we see the following plot show up:

Figure 3: The histogram generated from our heights data
It’s reassuring to see we have the right shape and we can already tell the mean of around \(68\) makes sense.
At the moment, this curve is way too noisy due to all the variances in the raw data we are using. To have any chance of obtaining an accurate area under the curve in a reasonable amount of time, we need to smooth this out.
For this, we will use a Savitzky-Golay filter
Figure 4: Animation showing smoothing being applied, passing through the data from left to right. The red line represents the local polynomial being used to fit a sub-set of the data. The smoothed values are shown as circles. Source: Wikipedia
{kind=link}
Savitzky-Golay uses least squares to regress small windows of the overall data onto polynomials. It works great with noisy samples from non-periodic and non-linear sources just like in our case!
First, import the algorithm:
from scipy.signal import savgol_filter
The savgol_filter function takes three parameters:
- The actual data you want to fit, in our case this will be
y - The size of the windows we want to regress one at a time, in our case, we only have 1000
y-values so we can’t choose a window size more than 999 (the window size must be odd) - The highest order polynomial to use when fitting windows
I find the bell curve shape allows us to use polynomails of order \(2\) and pretty big windows with pretty good accuracy. For instance, a window of \(999\) already kind of resembles the bell shape:

Figure 5: An order \(2\) polynomial fitting our bell curve.
Granted, it’s pretty terrible, but we are fitting the full data set with just one polynomial. What if we use \(5\) polynomials, each of order \(1\) or \(2\) instead?

Figure 6: Five polynomials, each of order either 1 or 2 fitting our bell curve.
Hey, that’s pretty good!
Now, do this just under where we’ve defined x and y but before we do stuff with plt:
window_size = N_BINS // 5 \
+ ((N_BINS//5) % 2 == 0) # Adjust to make the window size odd
y = savgol_filter(y, window_size, 2)
Now, we’ve read our data and managed to plot a pretty smooth bell curve out of it. Now it’s time to “squish” it down so its peak is exactly \(1\) and take the area under the curve. Squishing is easy, simply divide y by max(y). Just make sure to do this after the smoothing to get the best results:
y = y / max(y)
Now let’s take the area! We will be using the Trapezoidal method to do this.
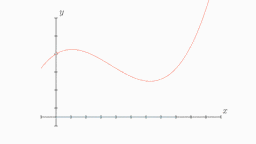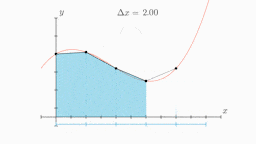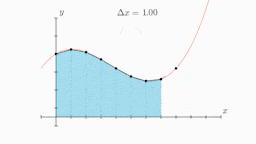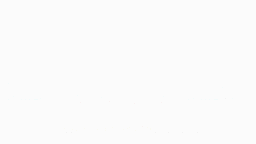
Figure 6: An animation demonstrating the Trapezoidal method. Source: Wikipedia
{kind=link}
The Trapezoidal method is a numerical technique for approximating the definite integral of a function, i.e. the area under its curve. It works by constructing very thin trapezoids that extend from the \(x\)-axis and meet the curve at that point. The above animation does a pretty good job of explaining this, and how using thinner and thinner trapezoids improves the accuracy of the resulting area.
Let’s do this now. Add this just under where we’ve done the squishing:
area = np.trapz(y, x=x)
print(area)
I got about 4.8:
$ python pi.py
4.769879246777704
Remember, should expect this number to be equal to
\[\int_{-\infty}^{\infty} e^{-\frac{1}{2}\left( \frac{x - \mu}{\sigma} \right)} = \sigma \sqrt{2 \pi}\]where \(\sigma\) is the standard deviation.
Let’s quickly check if this is right:
import statistics, math
sigma = statistics.stdev(heights)
print(sigma * math.sqrt(2 * math.pi))
Run this (keeping the previous print statement for the area we calculated so we can compare…)
$ python pi.py
4.769879246777704
4.766801777169521
So it looks like we’ve got the all clear to make the final calculation. Remember, to extract \(\pi\) from \(\sigma \sqrt{2 \pi}\) we must:
- Divide by \(\sigma\)
- Square the result
- Half the result
So here we go:
pi = (area / sigma) ** 2 / 2
print(pi)
…
$ python pi.py
3.145650416957449

Let’s see if we get the same degree of accuracy if we used weight data instead of height. Let’s replace heights with weights in our code and see what we get…
$ python pi.py
3.1192099437490493
Okay, not as good but still within the ballpark!
Conclusion
So this is definitely one of the least useful ways to calculate \(\pi\), but I find it is still pretty cool. If you think about it, all we’ve done is taken some data about human beings (height or weight), made a histogram, done some smoothing and squishing, and it turns out the area under the curve has \(\pi\) in it!
If you’d like to know how \(\pi\) shows up here, I would recommend checking out this video.
Thanks for reading! If you’d like to check out the complete source code, here’s the link to the GitHub repo!